Etapas del Diseño de Bases de Datos
Introducción
El diseño de bases de datos es un proceso fundamental en el desarrollo de sistemas de información. Según estudios, el 70% de los problemas de rendimiento en aplicaciones se originan en un diseño deficiente de la base de datos.
Ventajas de un buen diseño
- Reducción de redundancias hasta en un 90%
- Mejora del rendimiento en consultas complejas
- Facilidad de mantenimiento
Riesgos de un mal diseño
- Pérdida de integridad de datos
- Anomalías en actualizaciones
- Problemas de escalabilidad
Conceptos Básicos
Entidades
Objetos del mundo real (Ej: Cliente, Producto)
Atributos
Características de las entidades (Ej: nombre, precio)
Relaciones
Conexiones entre entidades (1:1, 1:N, N:M)
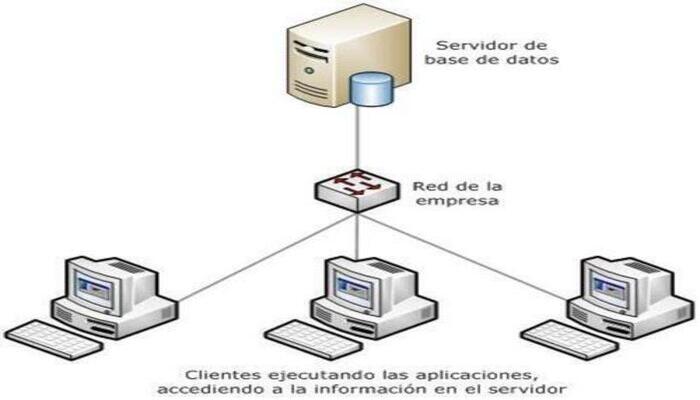
Figura 1: Ejemplo de diagrama E-R para un sistema de ventas 1

Diagrama que muestra las entidades con relaciones
Figura 2: Ejemplo de diagrama E-R para un sistema de ventas 2

Diagrama que muestra las entidades con relaciones
Características de un Diseño Óptimo
| Característica | Descripción | Beneficio |
|---|---|---|
| Normalización | Estructuración en formas normales (1FN, 2FN, 3FN) | Elimina redundancias y anomalías |
| Índices | Estructuras para acelerar búsquedas frecuentes | Mejora rendimiento en consultas |
| Integridad | Reglas como claves primarias/foráneas | Garantiza consistencia de datos |
Actividad Completa: Diseño de BD para Hospital
Paso 1: Requisitos del Sistema
Necesitamos almacenar información sobre:
- Pacientes (historial médico)
- Doctores (especialidades)
- Citas médicas
- Medicamentos recetados
Paso 2: Diagrama E-R para sistema hospitalario

Modelo con entidades Paciente, Doctor, Cita y Medicamento
Paso 3: Transformación a Esquema Relacional
-- Tabla Pacientes
CREATE TABLE Pacientes (
id_paciente INT PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
fecha_nacimiento DATE,
tipo_sangre VARCHAR(3)
);
-- Tabla Doctores
CREATE TABLE Doctores (
id_doctor INT PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
especialidad VARCHAR(50),
telefono VARCHAR(15)
);
-- Tabla Citas
CREATE TABLE Citas (
id_cita INT PRIMARY KEY,
id_paciente INT,
id_doctor INT,
fecha_hora DATETIME,
motivo VARCHAR(200),
FOREIGN KEY (id_paciente) REFERENCES Pacientes(id_paciente),
FOREIGN KEY (id_doctor) REFERENCES Doctores(id_doctor)
);
.......
.......
.......Paso 4: Normalización
1FN: Atributos atómicos
Dividir campos compuestos (ej: dirección en calle, ciudad, CP)
2FN: Dependencia completa
Eliminar atributos que dependen parcialmente de claves compuestas
3FN: Sin dependencias transitivas
Remover atributos que dependen de otros no clave (ej: edad → fecha_nacimiento)
Modelo Estrella (Data Warehouse)

Estructura para análisis con tablas de hechos y dimensiones

Diferencias en estructura y escalabilidad
Comparativa SQL vs NoSQL

Modelo con entidades Paciente, Doctor, Cita y Medicamento